- Published on
reinforcement learning course of hugging face
- Authors

- Name
- Sarsimour
Reinforcement Learning Course of Hugging Face( https://huggingface.co/learn/deep-rl-course/unit0/introduction )
This is the RL course by Hugging Face. The course is divided into 8 units. The course contains the following contents:
- Introduction to Reinforcement Learning
- Basic Concepts of Q Learning
- Deep Q Learning
- Policy Gradients
- Actor Critic
- Proximal Policy Optimization
- Multi-Agent Reinforcement Learning
- Optuna and Hyperparameter Tuning
What I learned
1. detail in deep q learning
we use deep q learning because it can handle large state spaces. The core step in deep q learning is to update the Q function. The Q function is updated by minimizing the difference between the target and the current Q function. The target is the reward plus the discounted max Q value for the next state. The loss function is the mean squared error between the target and the current Q function. 
2. Optuna
Optuna is a tool to find Hyperparameters quickly, here is an example:
import torch
import optuna
# 1. Define an objective function to be maximized.
def objective(trial):
# 2. Suggest values of the hyperparameters using a trial object.
n_layers = trial.suggest_int('n_layers', 1, 3)
layers = []
in_features = 28 * 28
for i in range(n_layers):
out_features = trial.suggest_int(f'n_units_l{i}', 4, 128)
layers.append(torch.nn.Linear(in_features, out_features))
layers.append(torch.nn.ReLU())
in_features = out_features
layers.append(torch.nn.Linear(in_features, 10))
layers.append(torch.nn.LogSoftmax(dim=1))
model = torch.nn.Sequential(*layers).to(torch.device('cpu'))
...
return accuracy
# 3. Create a study object and optimize the objective function.
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)
3. policy gradient
Actor-Critic methods, a hybrid architecture combining value-based and Policy-Based methods that helps to stabilize the training by reducing the variance using:
- An Actor that controls how our agent behaves (Policy-Based method)
- A Critic that measures how good the taken action is (Value-Based method)
a step to update actor network  a step to update critic network
a step to update critic network 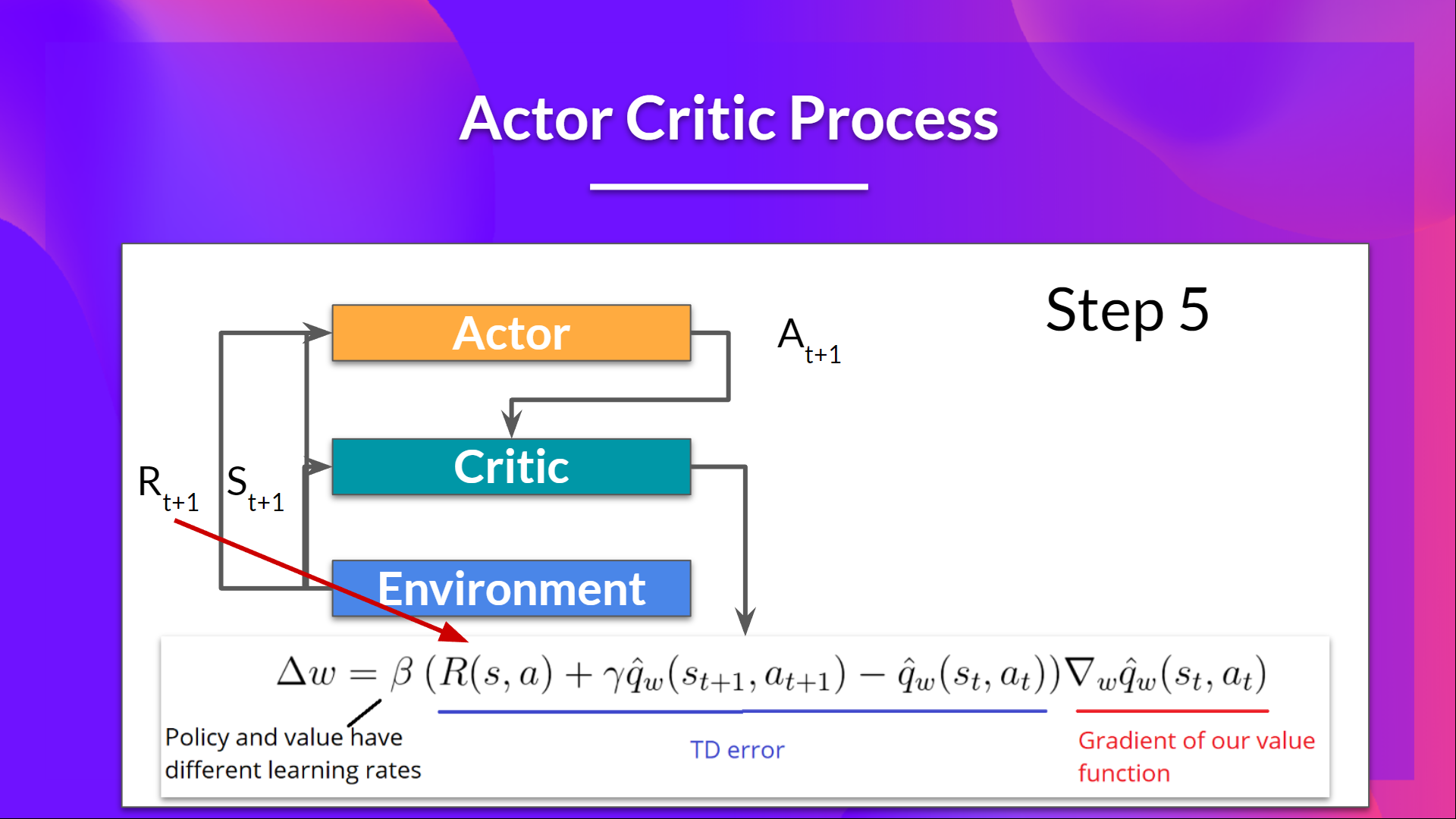
Advantage function
Advantage function is the difference between the Q value and the value function. The value function is the expected sum of rewards from a state. The advantage function is used to measure how good an action is compared to the average action. The meaning of advantage function is we want to get bigger chance to act actions better than average. And there are some variaties of advantage function, such as GAE, n-step advantage, etc. GAE is a way to estimate the advantage function, which is a weighted sum of the n-step advantage function. The weight is the lambda parameter, which is a hyperparameter. The lambda parameter is used to balance the bias and variance of the advantage function.
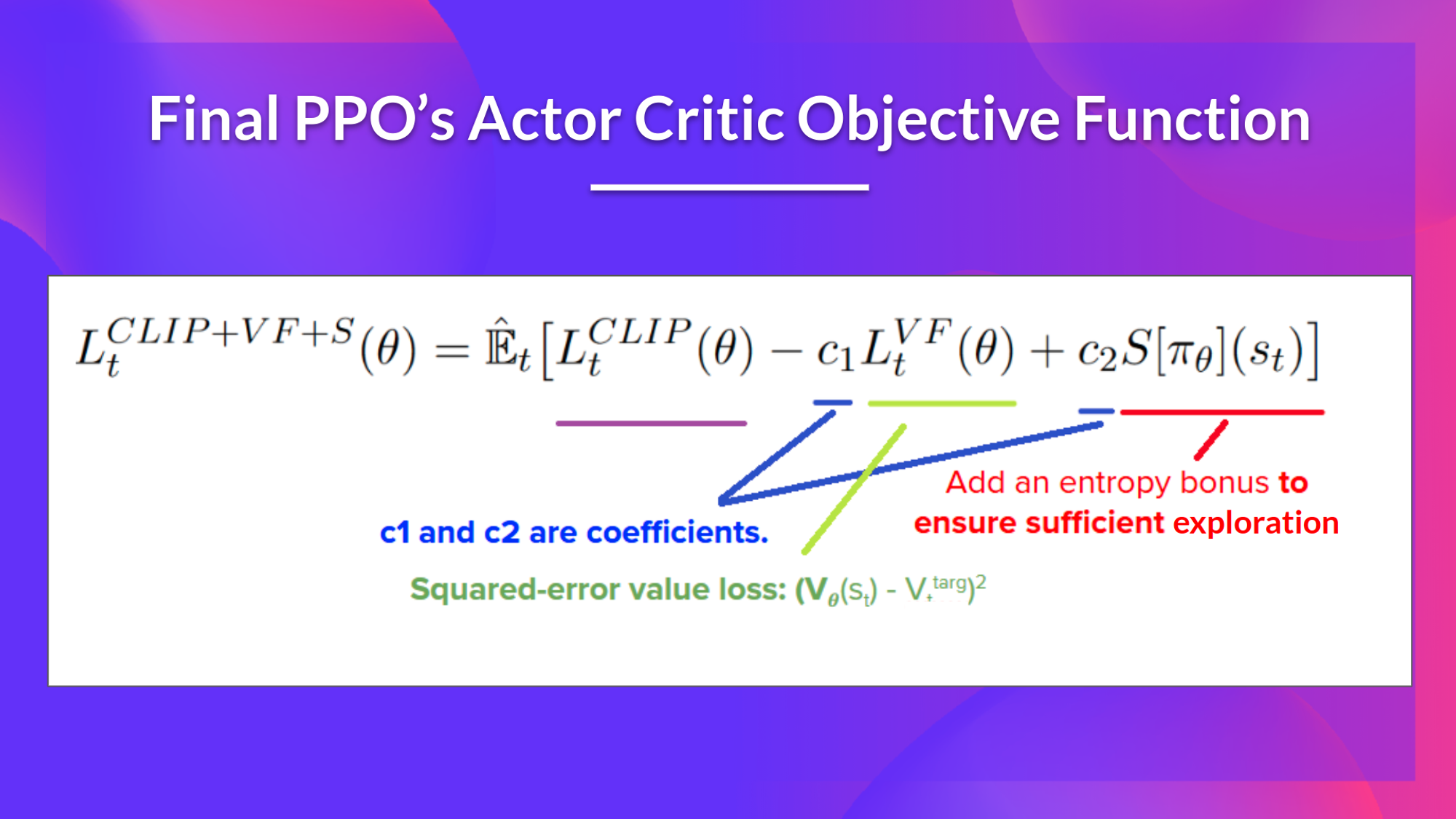
4. PPO
PPO means we would keep the policy close to the old one by clip the change ratio of action possibility under new and old policies. The core step of PPO is to update the policy by minimizing the loss function. The loss function is the minimum of the ratio of the new policy and the old policy and the advantage function. The ratio of the new policy and the old policy is used to measure how much the new policy is different from the old policy. The advantage function is used to measure how good the action is compared to the average action.